




![]()
The most important problem that we face as software professionals is this: If somebody thinks of a good idea, how do we deliver it to users as quickly as possible?[1]
—Continuous Delivery
CALMR
This is the second article in the SAFe DevOps series. It describes the shared mindset and values that underpin successful DevOps. See also the DevOps home page and SAFe’s DevOps Practice Domains.
SAFe’s CALMR approach to DevOps is a mindset that guides ARTs toward achieving continuous value delivery by managing simultaneous advancements in delivery culture, automation, lean flow, measurement, and recovery.
Successful DevOps hinges on an approach that unites everyone in the value stream toward achieving extraordinary business outcomes. In SAFe, CALMR provides such an approach. When everyone in the value stream thinks and acts with continuous delivery in mind, the result is:
- Increased frequency, quality, and security of product innovation
- Decreased deployment risk with accelerated learning cycles
- Accelerated solution time-to-market
- Improved solution quality and shortened lead time for fixes
- Reduced severity and frequency of failures and defects
- Improved Mean Time to Recover (MTTR) from production incidents
A critical component of this mindset is the realization that DevOps often forces a significant amount of change within established enterprises. Enterprises are complex systems with a broad diversity of people, values, processes, policies, and technology. Careful attention must be given to how to effectively cultivate and mature DevOps in these environments.
After more than a decade of experimentation and learning in this regard, the DevOps community has discovered that effective DevOps entails a deep appreciation for culture, automation, lean flow, measurement, and sharing (CALMS). In other words, DevOps requires that energy be directed toward each of these areas—not necessarily equally, but in balance—to achieve desired outcomes.
SAFe echoes this belief, with one modification: sharing is a natural component of culture, which makes room for ‘recovery’ as a new element. Hence, SAFe’s ‘CALMR’ approach to DevOps (Figure 1).
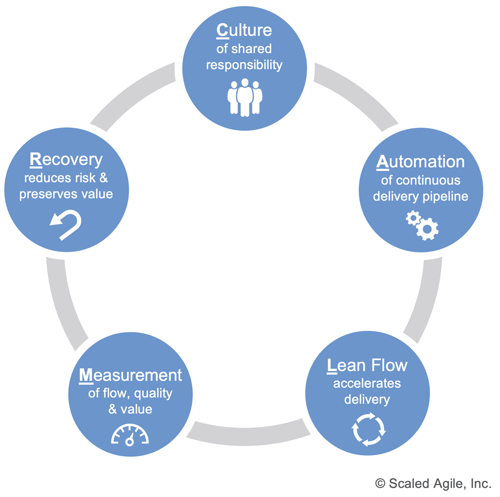
CALMR includes five elements that serve as pillars of DevOps excellence. These elements guide the decisions and actions of everyone involved in enabling continuous value delivery.
Details
Culture
In SAFe, DevOps leverages the culture created by adopting the Lean-Agile values, principles, and practices of the entire framework. Nearly every principle of SAFe, from Principle #1 – Take an economic view to Principle #10 – Organize around value, applies to DevOps. DevOps enables shifting some operating responsibilities upstream, while following development work downstream into deployment, and operating and monitoring the solution in production. Such a culture requires:
- Customer-centricity – Value is determined by an enterprise’s ability to sense and respond to customer needs; therefore, everyone in the value stream must be guided by a shared understanding of the customers they serve.
- Collaboration – DevOps relies on the ability of development, operations, security, and other teams to partner effectively on an ongoing basis, ensuring that solutions are developed, delivered, and maintained in lock step with ever changing business needs.
- Risk tolerance – DevOps requires widespread acknowledgment that every release is an experiment until validated by customers, and that many experiments fail. DevOps cultures reward risk taking, continuous learning, and relentless improvement.
- Knowledge sharing – Sharing ideas, discoveries, practices, tools, and learning across teams, ARTs and the wider organization unifies the organization and enables skills to shift left.
Automation
DevOps recognizes that manual processes are the enemy of fast value delivery, high productivity, and safety. This is because manual processes tend to increase the probability of errors in the delivery pipeline, particularly at scale. These errors in turn cause rework, which delays desired outcomes.
Automating the Continuous Delivery Pipeline via an integrated ‘tool chain’ (Figure 2) accelerates processing time and shrinks feedback cycles. It is this feedback—from customers, stakeholders, solutions, infrastructure, and the pipeline itself—that provides objective evidence that solutions are (or are not) delivering expected value.
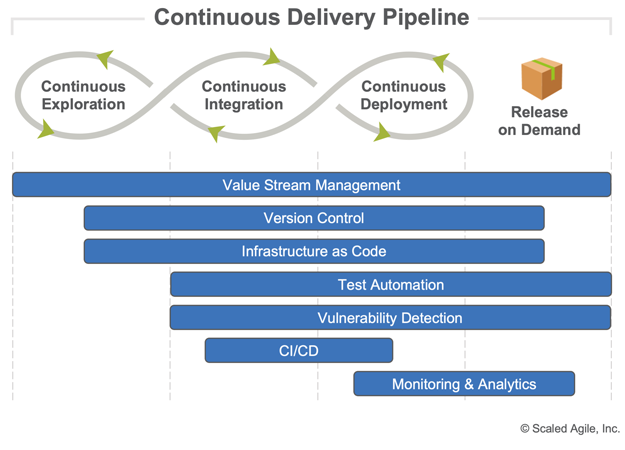
Building and operating a continuous delivery pipeline tool chain typically involves the following categories of tools:
- Value Stream Management (VSM) – VSM tools ‘wrap’ the continuous delivery pipeline from end to end, providing real time visibility into the health and efficiency of the value stream itself.
- Version Control – These are tools that store and manage changes to source and configuration files that define the behavior of solutions, systems, and infrastructure.
- Infrastructure as code (IaC) – As a discipline, infrastructure-as-code treats all systems as highly configurable, expendable commodities. Tools in this category enable all manner of computing infrastructure to be built, deployed, changed, and destroyed on demand.
- Test Automation – Test automation can be a significant source of delivery acceleration and typically applies to all forms of unit, component, integration, regression, performance, acceptance, and usability testing except exploratory testing.
- Vulnerability Detection – These tools span much of the continuous delivery pipeline and are specifically designed to detect security vulnerabilities in code, networks, and infrastructure.
- CI/CD – Continuous integration (CI) and continuous delivery (CD) tools are typically invoked automatically upon code commit and orchestrate build, integration, testing, compliance, and deployment activities.
- Monitoring and Analytics – These tools collect usage and performance data from all levels of the solution stack and provide critical insights into pipeline flow, solution quality, and delivered value.
- Additional tools – The tools above tend to be used universally; however, there are many others that support DevOps but are very implementation specific. These fall into categories such as IDE plugins, microservices, artifact repositories, cloud management, and chaos engineering.
Lean Flow
Agile teams and trains strive to achieve a state of continuous flow, enabling new features to move quickly from concept to cash. The three keys to accelerating flow are reflected in the name of Principle #6 – Visualize and limit WIP, reduce batch sizes, and manage queue lengths. All three are integral to the ongoing optimization of the continuous delivery pipeline. Each is described below in the context of DevOps.
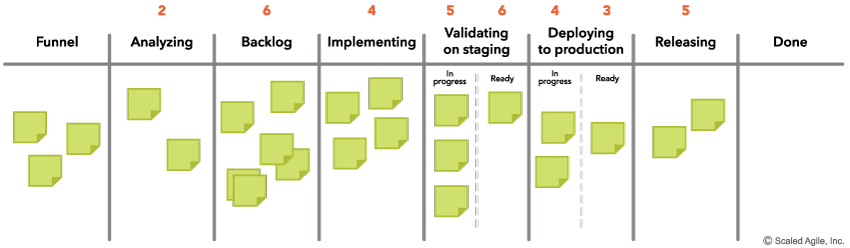
- Visualize and limit Work in Process (WIP) – Figure 3 illustrates an example of a Program Kanban board, which makes WIP visible to all stakeholders. This helps teams quickly identify bottlenecks and balance the amount of WIP against the available development and operations capacity.
- Reduce batch sizes – Small batches go through the system faster and with less variability than large batches. This supports more frequent deployments and speeds the learning process. Reducing batch sizes typically involves focusing more attention on, and increasing investment in, infrastructure and automation that reduces the transaction cost of each batch.
- Manage queue lengths – The size of the queue of work to be done is a predictor of the amount of time it will take to complete the work, no matter how efficiently that work is processed. Fast flow is achieved by closely managing, and generally reducing, queue lengths. The shorter the queue, the faster the delivery.
Measurement
Achieving extraordinary business outcomes with DevOps requires the continuous delivery pipeline to be highly optimized. Solutions, the systems on which they run, and the processes by which they are delivered and supported must be frequently fine-tuned for maximum performance and value.
What to optimize, how to optimize it, and by how much are decisions that need to be made on a near-constant basis. These decisions are rooted in Principle #1 – Take and economic view and Principle #5 – Base milestones on objective evaluation of working systems, not merely on intuition. Thus, the ability to accurately measure delivery effectiveness and feed that information back into relentless improvement efforts is critical to DevOps success.
Given this, what metrics should be tracked and from what sources? While every enterprise and delivery pipeline are different, the following popular guidelines tend to apply universally.
- Measure pipeline flow – The health of the delivery pipeline itself can make or break a solution. It is the Development Value Stream and must evolve into a continuous delivery pipeline for business agility to be achieved. Flow measurements focus on throughput and lead time from concept (customer request) to cash (delivery to customer) and are derived from the people and tools that perform design, development, testing, deployment, and release activities. For example, Mik Kersten’s Flow Framework defines four “Flow Metrics”–flow velocity, flow efficiency, flow time, and flow load–and tracks the “Flow Distribution” of features, defects, risks, and debts in the pipeline.[2] Google lists end-to-end lead time and deployment frequency as the most important indicators of pipeline performance.[3]
- Measure solution quality – DevOps cultures stress the importance of shifting technical practices left. This is to ensure that quality is built into solutions during development rather than ‘inspected in’ as defects are discovered later. Quality metrics gauge adherence to functional, non-functional, security, and compliance requirements and are best obtained via automated testing tools prior to release. The Flow Framework categorizes these loosely as quality metrics [2] while Google focuses specifically on change fail rates.[3]
- Measure solution value – A streamlined pipeline is worthless if it simply accelerates the delivery of products nobody wants. Therefore, measuring the business value of the work exiting the pipeline is essential. These metrics gauge economic outcomes and customer (or end user) satisfaction and are evaluated against forecasted outcomes defined as part of the original business hypothesis. Value metrics are sourced from full-stack telemetry, analytics engines, financial systems, and feedback from users and stakeholders. The Flow Framework presents these as “Business Results” with specific metrics to track value, cost, and happiness.[2] Google adds time to restore—equivalent to the well known Mean Time to Restore (MTTR)—since production failures can very rapidly diminish the value of deployed solutions.[3]
Recovery
To support frequent and sustained value delivery, the continuous delivery pipeline must be designed for low-risk releases and fast recovery from operational failure. Techniques to achieve a more flexible release process are described in the Release on Demand article. In addition, the following techniques support fast recovery:
- Stop-the-line mentality – With a ‘stop-the-line’ mentality, any issue that compromises solution value causes team members to stop what they are doing and swarm on the issue until it is resolved. Learnings are then turned into permanent fixes to prevent the issue from recurring.
- Plan for and rehearse failures – When it comes to DevOps, failed deployments are not only an option, they are expected from time to time. To minimize the impact of failures and maximize the resiliency of solutions, teams should develop recovery plans and practice them often in production or production-like environments. (See ‘Chaos Monkey’[4].)
- Fast fix forward and roll back – Since production failures are inevitable, teams need to develop the capability to quickly ‘fix forward’ and, where necessary, roll back to a known stable state. Fixes must flow through the same process as any feature or enhancement; therefore, it is imperative that the continuous delivery pipeline is able to accommodate any type of change at any level of severity.
Typically, architecture, infrastructure, and skills challenges need to be addressed to enable fast, elegant recovery. Organizations often undertake special enterprise-level initiatives to evolve these capabilities.
More in the DevOps Series
Article 1: DevOps Main Page
Article 2: A CALMR Approach to DevOps
Article 3: SAFe’s DevOps Practice Domains
Learn More
[1] Humble, Jez, and David Farley. Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation. Addison-Wesley. [2] Kersten, Mik. Project to Product: How to Survive and Thrive in the Age of Digital Disruption with the Flow Framework. IT Revolution Press. [3] Accelerate – State of DevOps 2019. https://services.google.com/fh/files/misc/state-of-devops-2019.pdf [4] The Netflix Simian Army. https://netflixtechblog.com/the-netflix-simian-army-16e57fbab116
Last update: 10 February 2021