




![]()
Imagine a world where product owners, Development, QA, IT Operations, and Infosec work together, not only to help each other, but also to ensure that the overall organization succeeds. By working toward a common goal, they enable the fast flow of planned work into production, while achieving world-class stability, reliability, availability, and security. [1]
—The DevOps Handbook
DevOps
This is the home page for the SAFe DevOps series, which consists of three articles. It is an introduction to foundational DevOps concepts in SAFe. Also read about CALMR and SAFe’s DevOps Practice Domains.
DevOps is a mindset, a culture, and a set of technical practices. It provides communication, integration, automation, and close cooperation among all the people needed to plan, develop, test, deploy, release, and maintain a Solution.
DevOps is part of the Agile Product Delivery competency of the Lean Enterprise.
DevOps is a combination of two words: development and operations. Without DevOps, there is often significant tension between those who build Solutions and those who support and maintain those solutions. SAFe enterprises implement DevOps to break down organizational silos and develop a Continuous Delivery Pipeline (CDP) —a high-performance innovation engine capable of delivering market-leading solutions at the speed of business.
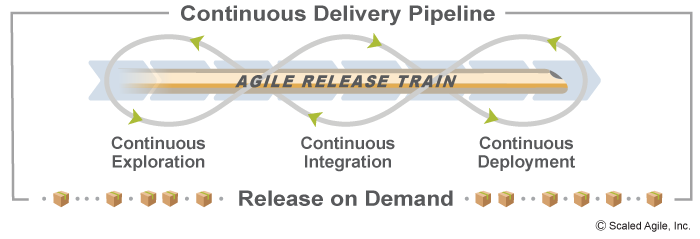
The goal is simple: deliver value whenever there is a business need. This is indeed achievable, as teams that excel at DevOps, on average, deploy 208 times more frequently, deploy 106 times faster, experience 7 times fewer failures, and recover from incidents 2,604 times faster than low performing teams. [2]
DevSecOps
DevSecOps is a term that emphasizes the importance of sound information security practices in the pursuit of continuous delivery. Because the origins of DevOps did not explicitly include security as a top-level concern (as it did for development and operations) DevSecOps has emerged as a popular label that avoids any risk of security being an afterthought.
The security community has been instrumental in evolving DevOps thinking beyond its development and operations roots. The State of DevOps Report—the world’s longest-running and most widely cited DevOps research project—has revealed that an organization’s security posture improves when security is completely integrated into the value stream. [3] In one of the most-read DevSecOps primers on the Internet, RedHat reminds us that “outdated security practices can undo even the most efficient DevOps initiatives.” [4] The Open Web Application Security Project’s (OWASP) Top 10 list of software vulnerabilities has become a go-to tool for fostering collaboration between development, operations, and security teams. [5] Through its pioneering Enterprise DevSecOps Platform (DSOP) initiative, the US Air Force has demonstrated that combining advanced DevOps and security practices can provide some of the most staunchly regulated organizations in the world ‘plug and play’ software factories and radically streamlined delivery processes.
These are just a few examples of how the DevSecOps movement has collectively created a rising tide that has lifted DevOps to new standards of excellence. It reminds us that building security into solutions is as important as building quality in, that security knowledge should flow left to prevent vulnerabilities, and that security tests should be automated to increase the speed and accuracy of compliance.
Thanks to these contributions, security has become ingrained in DevOps culture, so much so that the meanings of DevOps and DevSecOps have become, for all intents and purposes, indistinguishable. Each implies a set of blended practices from multiple domains—development, operations, security, infrastructure, architecture, and so on throughout the value stream—that work together to enable collaboration, speed, quality, and safety.

SAFe carries this sentiment forward, treating security as a first-class citizen. In SAFe, to say “DevOps” is to mean “DevSecOps.” Protecting our customers, employees, citizens, soldiers, families, and businesses is not something we choose to do or not do in DevOps. It is simply in our DNA. As such, modern security practices shine through in many areas of SAFe, including the Big Picture, framework guidance, courseware, assessments, advanced topics articles, and more.
Details
DevOps makes continuous delivery possible. Enterprises that wish to deliver truly continuous value to their customers and stakeholders need to master the mindset and technical practices of DevOps. In this era of constant digital disruption and innovation, these skills are table stakes. But achieving continuous delivery, especially at scale, is not easy. SAFe’s approach to DevOps helps enterprises navigate these complexities.
A Paradigm Shift
IT organizations worldwide are plagued by a core, chronic conflict: technology delivery processes that are reliant on teams with opposing goals and incentives[1]. Agile teams must deliver changes quickly to keep pace with business needs. Operations teams must regulate the flow of changes to maintain the stability of solutions that run the business. Security teams must institute policies to prevent changes from introducing vulnerabilities that can cause data breaches.
To correct this, a new delivery system is needed—a ‘software factory’ that aligns teams and increases delivery speed while simultaneously increasing solution quality, security, and stability. Only then can the needs of all teams and the needs of the customer be met predictably and effectively.
Note: ‘Software factory’ is an increasingly popular term used to refer to this new kind of delivery system. In his advanced topic article, Peter Vollmer describes a software factory as “standardized tooling and engineering services that support and enhance [the value stream].” [6] These factories are integrated sets of tooling, services, data, and processes that help move product through plan, build, test, and release cycles. [7] The US Department of Defense (DoD) maintains a growing ecosystem of software factories, each of which leverages a common DevSecOps platform (DSOP) to rapidly deliver specialized digital products and services. [8] Regardless of the term used to describe the system, enterprises leverage DevOps to achieve this level of sophistication in their value streams.
Unfortunately, most IT organizations do not natively support this kind of system. Their processes and policies are optimized to prevent frequent changes to production systems, not enable them. Hence, a paradigm shift is needed. Just as Agile represents a paradigm shift in the way we work, DevOps represents a paradigm shift in the way we build. Leveraging DevOps to usher in a new way of building digitally-enabled solutions is the key to transforming antiquated development life cycles into continuous delivery pipelines.
Continuous Learning and Experimentation
Continuous delivery pipelines are the result of applying DevOps effectively to value streams. And today’s value streams must behave differently than they did in the old paradigm, largely because today’s technology delivery objectives are different.
To be sure, enterprises are under pressure to release features faster than ever to remain relevant in their markets. But out-deploying the competition is not the goal. Out-learning them is. And that learning comes from understanding the value those features have in the market. Since a feature has no value until it is released, today’s enterprises must be in a constant cycle of building, measuring, and learning to quickly evolve digital solutions that attract and retain customers. As depicted in Figure 3, SAFe’s Continuous Delivery Pipeline operates as a closed loop that fosters rapid, low-risk experimentation and continuous learning about customers’ needs, habits, and preferences.
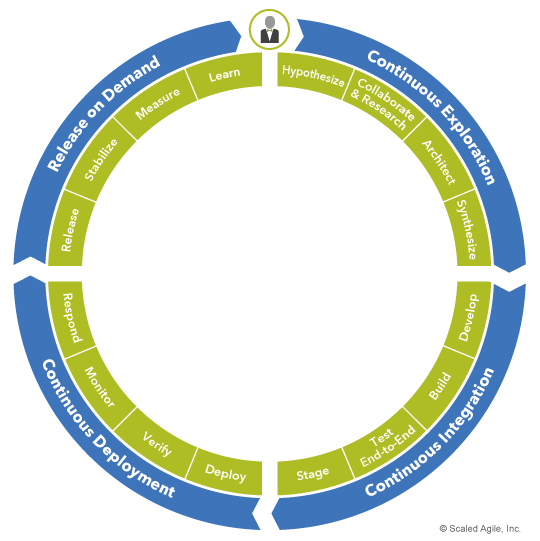
This perpetual learning and experimentation engine is starkly different than traditional, waterfall-style delivery processes. Enabling it requires a different mindset, different skills, and different tools across the entire value stream. Large batches, siloed teams, cold handoffs, monolithic architectures, review boards, politics, and heroics have no place here. Instead, this new system must be fueled by shared values, cross-functional collaboration, objective measurements, automation, and modern technical practices.
Enter DevOps.
As illustrated in Figure 4, DevOps enables the continuous delivery pipeline. It does this by supplying the mindset, practices, and tooling required to foster rapid delivery and learning at every step.
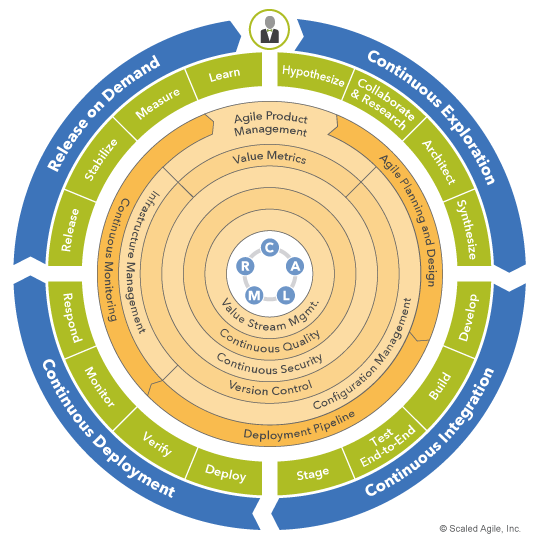
At its core, DevOps is a mindset that guides behavior and decision making throughout the value stream. SAFe’s CALMR approach to DevOps embodies this mindset, is central to the figure, and permeates all aspects of the continuous delivery pipeline. DevOps technical skills, practices, and tooling evolve and sustain solutions directly. In SAFe, they are grouped into practice domains, which are represented by the inner rings of the model.
For a deeper understanding of how CALMR and the practice domains enable the continuous delivery pipeline, continue exploring this DevOps series.
Measuring and Managing DevOps Maturity
Measuring DevOps performance and tracking incremental progress are important steps in building a thriving DevOps culture.
The SAFe DevOps Health Radar (Figure 5) is a tool that helps ARTs and Solution Trains optimize their value stream performance. It provides a holistic DevOps health check by assessing the maturity of the four aspects and 16 activities of the continuous delivery pipeline. The Health Radar is used to measure baseline maturity at any point in a DevOps transformation and guide fast, incremental progress thereafter.
DevOps Health Radar
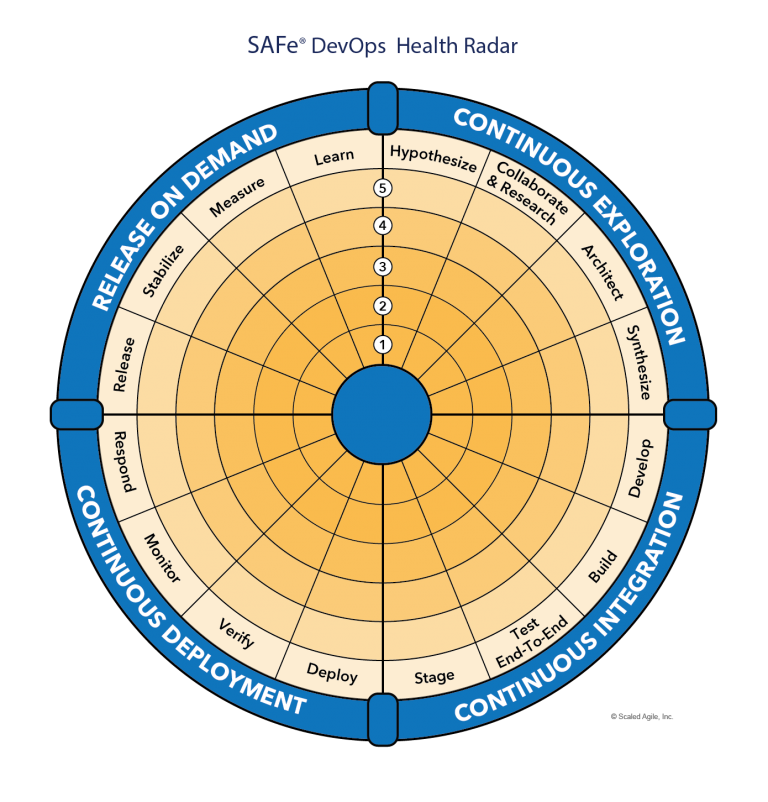
Download the free DevOps Health Radar assessment here. Agility Health, a Scaled Agile partner, also offers an online version of this assessment.
More in the DevOps Series
Article 1: DevOps Home Page
Article 2: A CALMR Approach to DevOps
Article 3: SAFe’s DevOps Practice Domains
Learn More
[1] Kim, Gene, Jez Humble, Patrick Debois, and John Willis. The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. IT Revolution Press, 2016. [2] Accelerate – State of DevOps 2019. https://services.google.com/fh/files/misc/state-of-devops-2019.pdf [3] 2019 State of DevOps Report. https://puppet.com/resources/report/2019-state-of-devops-report [4] What is DevSecOps? https://www.redhat.com/en/topics/devops/what-is-devsecops [5] OWASP Top 10 Application Security Risks. https://owasp.org/www-project-top-ten/ [6] Accelerating Flow with DevSecOps and the Software Factory. /accelerating-flow-with-devsecops-and-the-software-factory/ [7] Why a Software Factory Is Key to Your DevOps Success. https://techbeacon.com/devops/why-software-factory-key-your-enterprise-devops-success [8] Software Factories. https://software.af.mil/software-factories/
Last update: 27 September 2021